Making interoperability easier with Pathling
 Our HL7® FHIR® based server eases the delivery of analytics-enabled apps and augments health data analytics tasks.
Our HL7® FHIR® based server eases the delivery of analytics-enabled apps and augments health data analytics tasks.
FHIR Analytics Server
Pathling, which provides a FHIR API, has many uses in health data analytics.
Pathling provides a FHIR API that allows you to import FHIR data then query it back out using FHIRPath expressions.
This API can be used to:
- power applications which enable exploratory data analysis,
- select and retrieve FHIR resources relating to a patient cohort definition,
- reshape and extract data in preparation for primary data analysis and training of machine learning models,
- and integrate advanced terminology features into analytic workflows, such as SNOMED CT Expression Constraint Language and the LOINC part hierarchy.
FHIRPath
FHIRPath is a graph traversal notation that makes it easy to traverse and interact with data within FHIR resources.
The tool makes it easy to select data from a graph of FHIR resources. It also provides a set of useful functions for dealing with FHIR data types and accessing terminology functionality.
A list of qualification codes of all the practitioners involved in an encounter.

Summarise
Reshape FHIR data into a customised extract file.
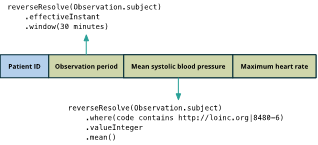
The tool allows users to reshape FHIR data into a customised extract file.
The summarise operation is designed for extracting data for use with other tools, such as statistical and machine learning models.
It takes a set of expressions which define columns in a tabular view of the data.
The operation returns a delimited text file containing the result of executing the expressions against each subject resource.
Aggregate
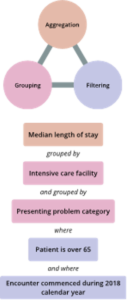
The tool enables users to retrieve grouped, aggregate results from FHIR data.
Retrieve grouped, aggregate results from FHIR data.
The aggregate operation is designed for exploratory data analysis and can be described as a “pivot table as an API”.
It returns a set of groupings and aggregate function results, along with links to drill down from each grouped result to the individual FHIR resources which were used to derive it.
Apache Spark integration
Integrate with Apache Spark to efficiently process data sets of arbitrary size.
Pathling can connect to an Apache Spark cluster, which will result in operations being distributed across workers for parallel execution.
Pathling supports S3 and HDFS file stores for efficient access of data from Spark workers.
The Australian e-Health Research Centre (AEHRC) is CSIRO's digital health research program and a joint venture between CSIRO and the Queensland Government. The AEHRC works with state and federal health agencies, clinical research groups and health businesses around Australia.